Dual-Process Distillation
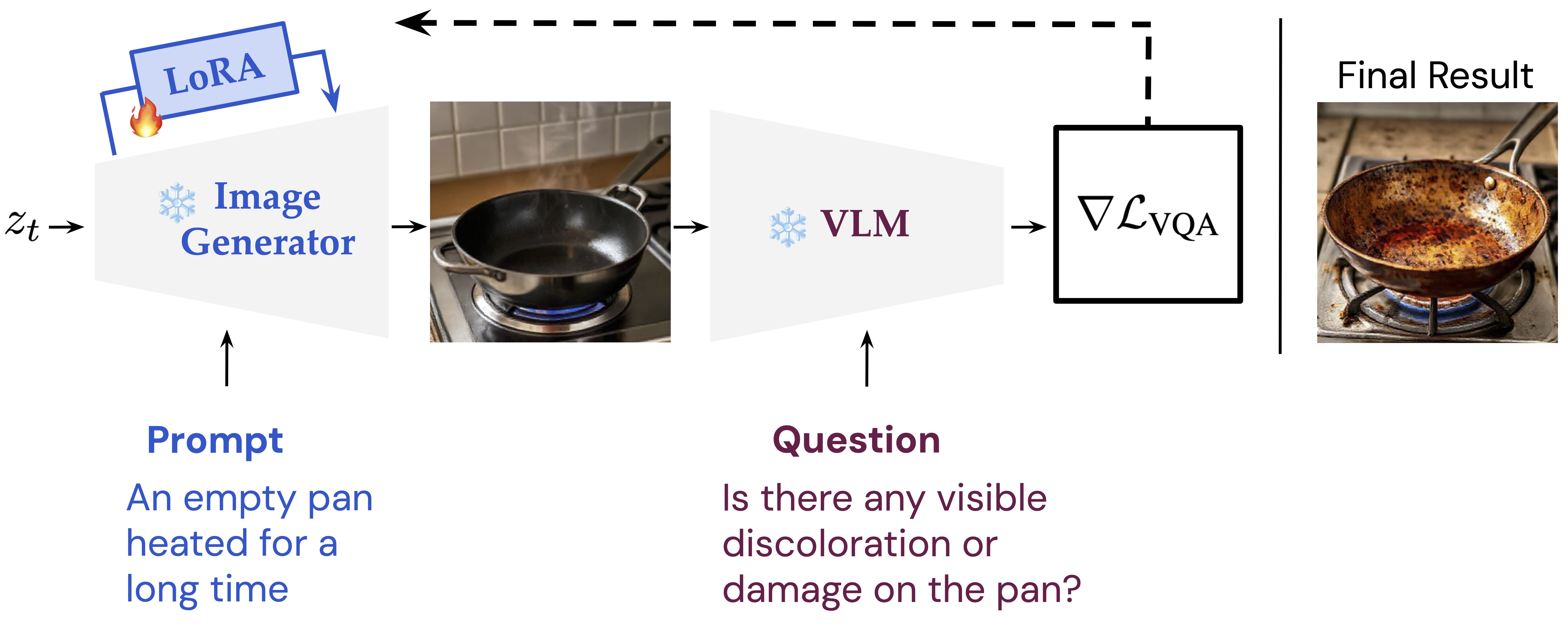
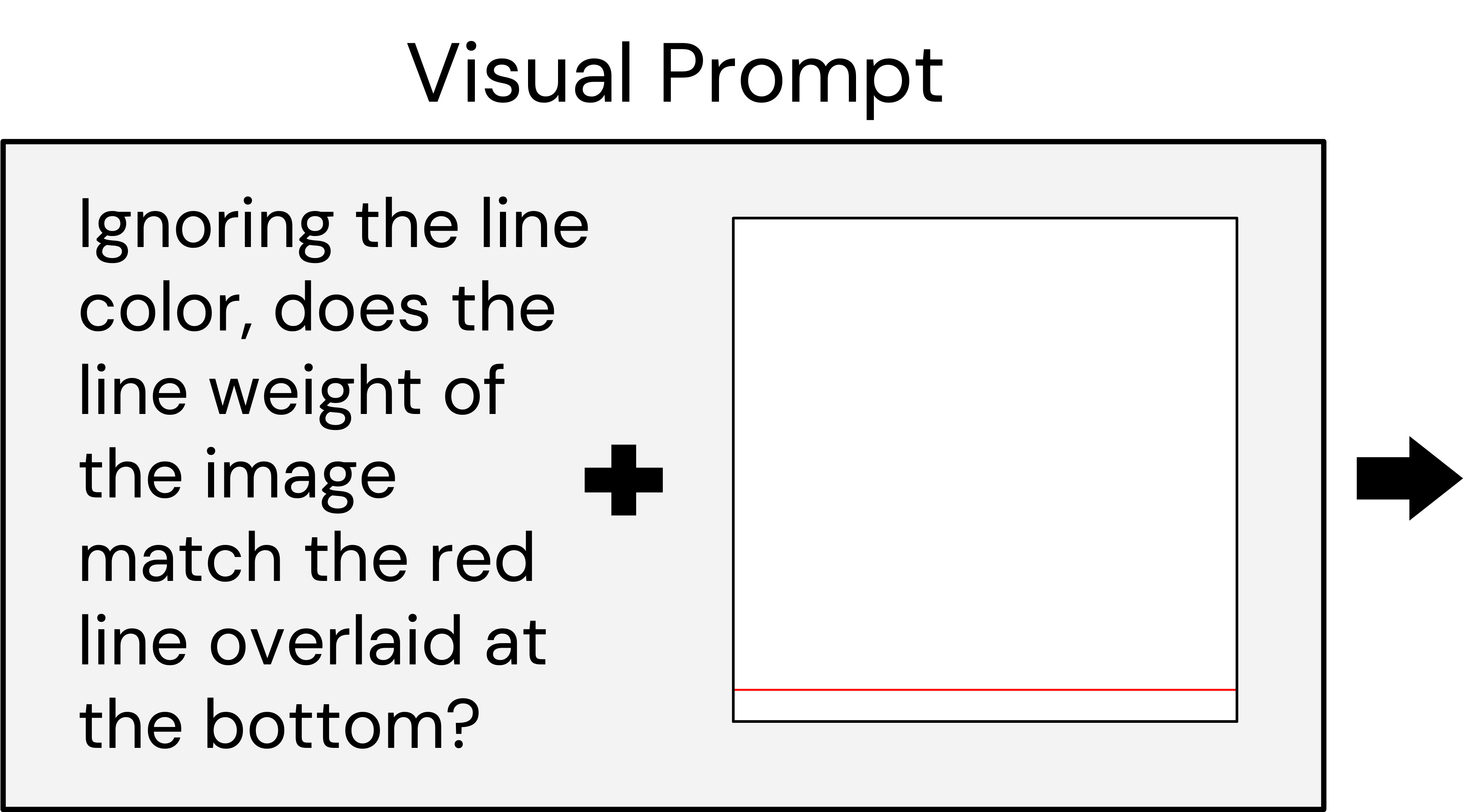
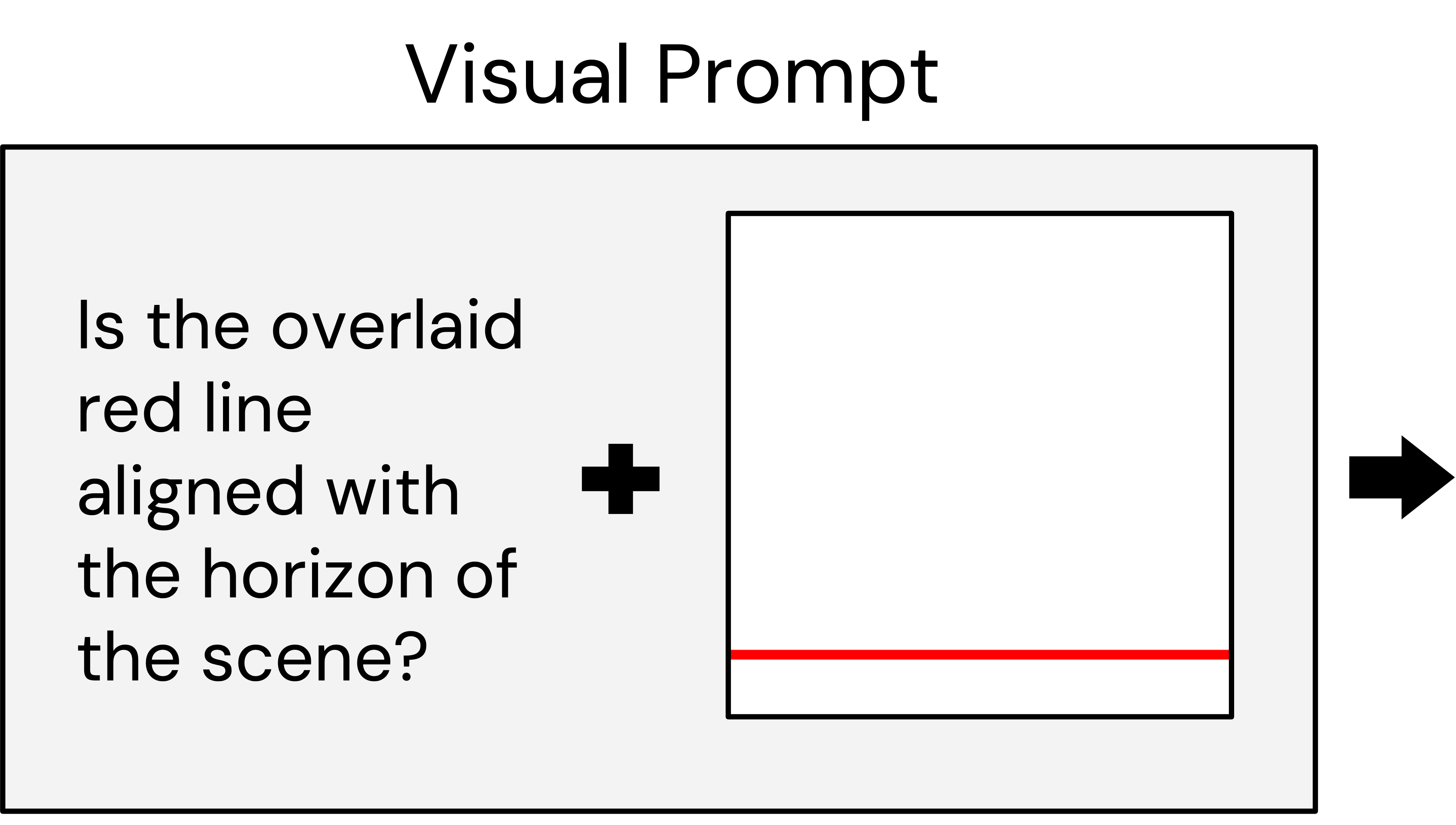
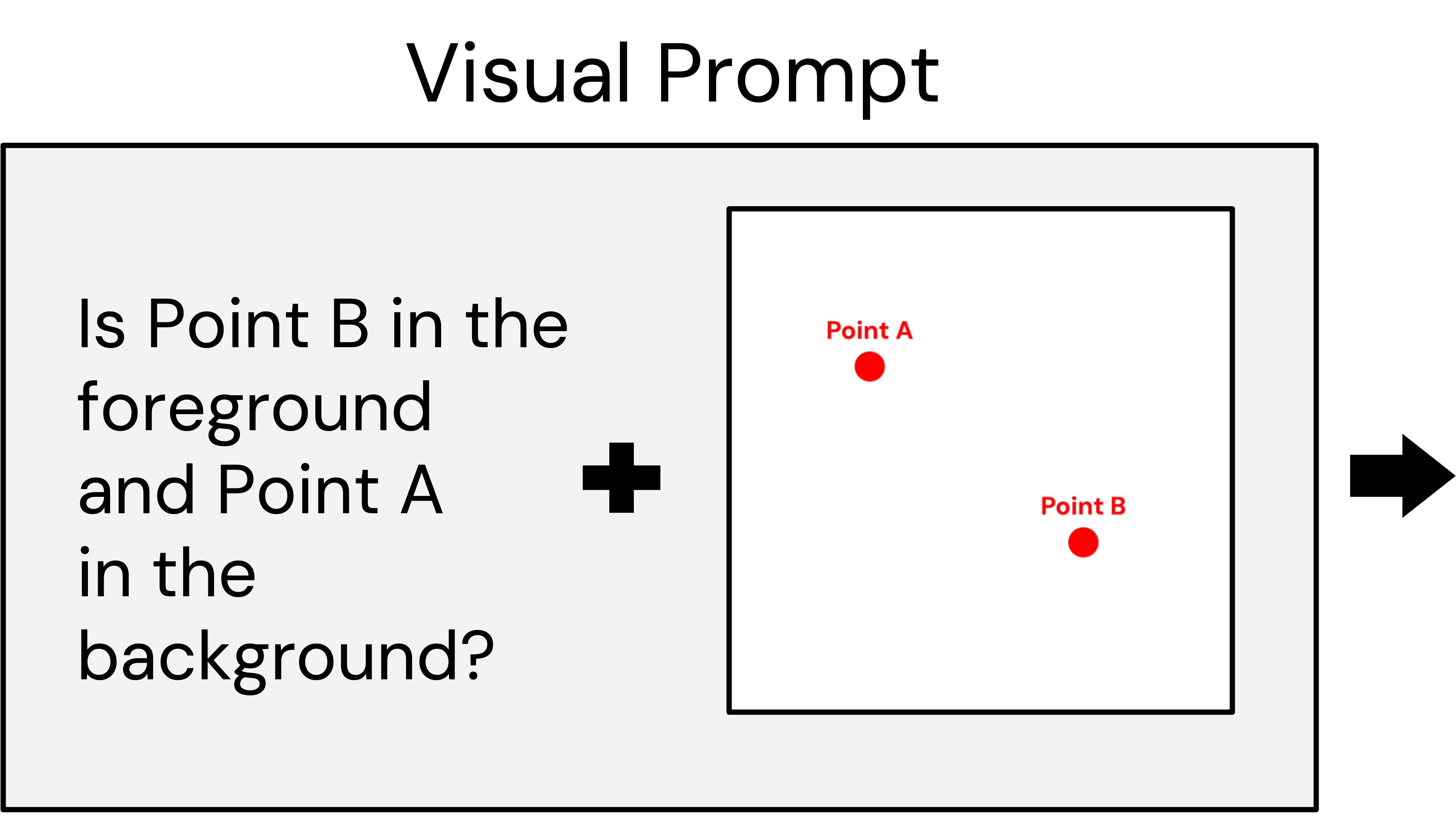
Our method distills deliberation into a feed-forward image generation process. When generating an image, we ask a VLM questions about that image and backpropagate the resulting gradient to update the weights of the image generator. We construct our method such that it supports off-the-shelf VLMs and image generators without special re-training.
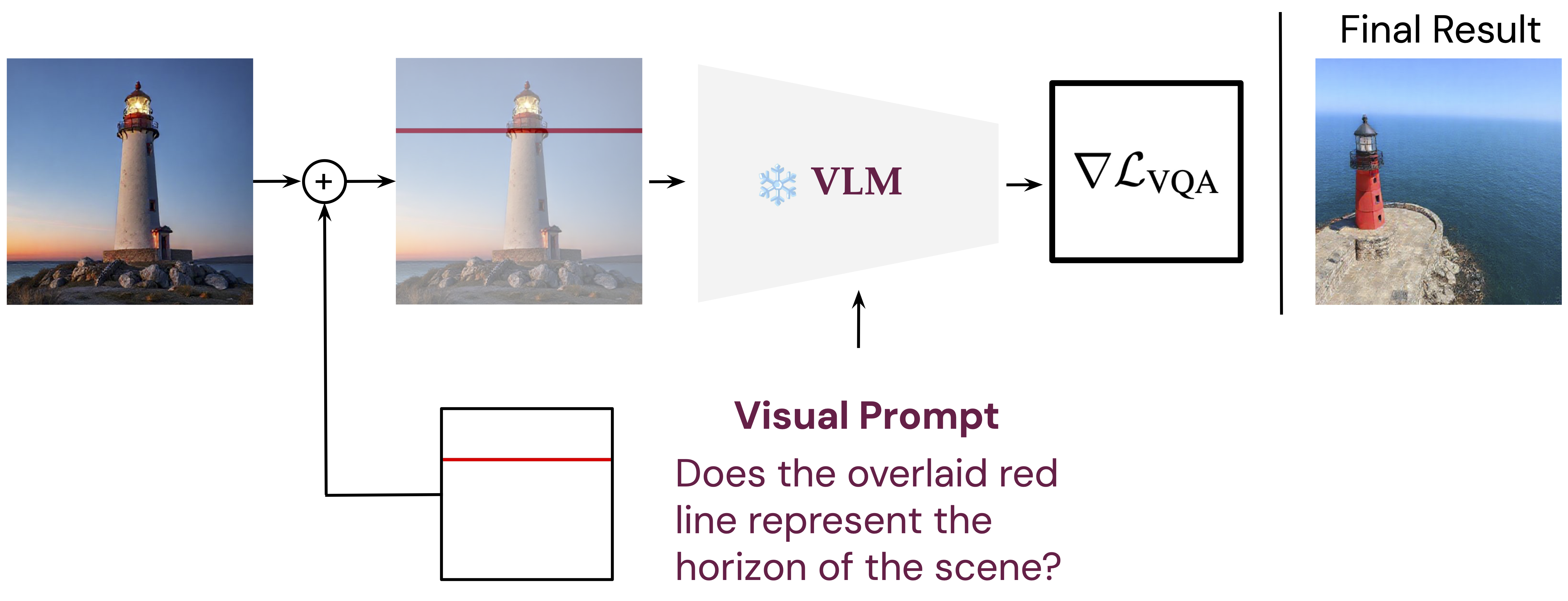
 Click the underlined text for dropdown menu
Click the underlined text for dropdown menu